At CDOps Tech, we recently helped a client improve the scalability of their Kubernetes-based data pipelines by integrating an open-source RabbitMQ autoscaler.
The result: faster ETL processing, lower cloud costs, and fully automated scaling.
The Challenge
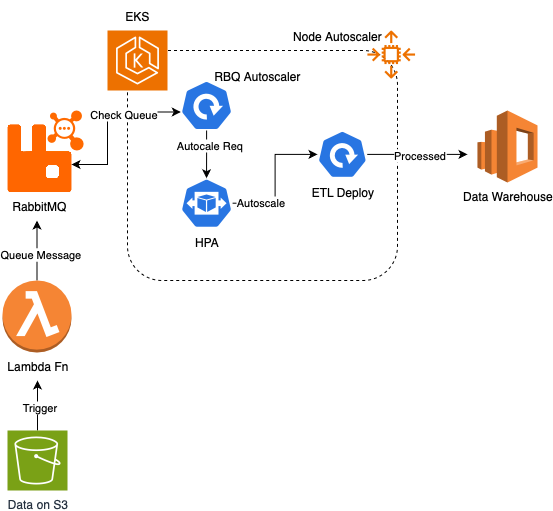
The client runs data pipelines that rely heavily on RabbitMQ queues to distribute ETL jobs across worker pods in Kubernetes.
However, scaling the workers was inefficient.
Scaling decisions were either manual or based on CPU utilization, which didn’t reflect the real workload — the queue backlog.
This created several issues:
- Over-provisioned workers when queues were quiet
- Job processing delays when queue traffic suddenly spiked
- Unnecessary cloud costs due to inefficient scaling
The Solution
We implemented an open-source RabbitMQ autoscaler designed for Kubernetes to enable queue-based autoscaling.
Instead of relying on CPU metrics, the system now scales based on actual queue depth in RabbitMQ.
When job queues grow, worker pods scale up automatically.
When queues empty, pods scale back down.
This ensures compute resources match real-time workload demand.
Key Implementation Steps
- Configured Kubernetes Horizontal Pod Autoscaler (HPA) using a Custom Metrics Adapter
- Exposed RabbitMQ queue depth metrics as Kubernetes custom metrics
- Implemented automatic scaling policies for ETL worker deployments
- Enabled dynamic scale-up/down based on live queue pressure
The system now reacts directly to message workload, not indirect signals.
The Impact
The improvements were immediate and measurable.
- Faster ETL Processing: Worker pods scale quickly during queue surges, clearing job backlogs much faster.
- Lower Cloud Costs: Workers automatically scale down when queues are idle, eliminating unnecessary compute usage.
- Zero Manual Scaling: Operations teams no longer need to intervene during traffic spikes.
- Cloud-Native Architecture: The solution follows modern Kubernetes best practices: observable, automated, and declarative.
Technology Stack
- Kubernetes
- RabbitMQ
- Open-Source RabbitMQ Kubernetes Autoscaler
- Kubernetes Metrics API
- Python-based ETL Workers
Key Takeaway
Scaling data pipelines should be driven by demand, not guesswork.
By introducing queue-aware autoscaling, we built a more responsive and cost-efficient pipeline architecture that keeps data workflows fast, reliable, and resource-efficient.

