Client:
Early-stage B2B SaaS company (NDA)
Team:
8 engineers
Cloud:
AWS
Stack:
Node.js, React, PostgreSQL, Redis
An early-stage SaaS company with a team of 8 engineers approached CDOps Tech as their platform started growing and deployments were becoming harder to manage.
Their stack included Node.js, React, PostgreSQL, and Redis, running on AWS.
While the product was evolving quickly, the infrastructure was still being deployed manually, creating reliability risks and slowing down releases. The team needed a scalable solution that could support rapid development without hiring a full-time DevOps engineer.
The Challenge
The engineering team was deploying services manually to EC2 instances.
As the product grew, the process became risky and time-consuming. Every release carried the possibility of downtime.
Key issues included:
- Frequent downtime during deployments
- Inconsistent environments between staging and production
- Manual scaling with no automatic recovery
- Limited visibility and monitoring of workloads
This slowed down development and made it harder for the team to ship updates confidently.
The Solution
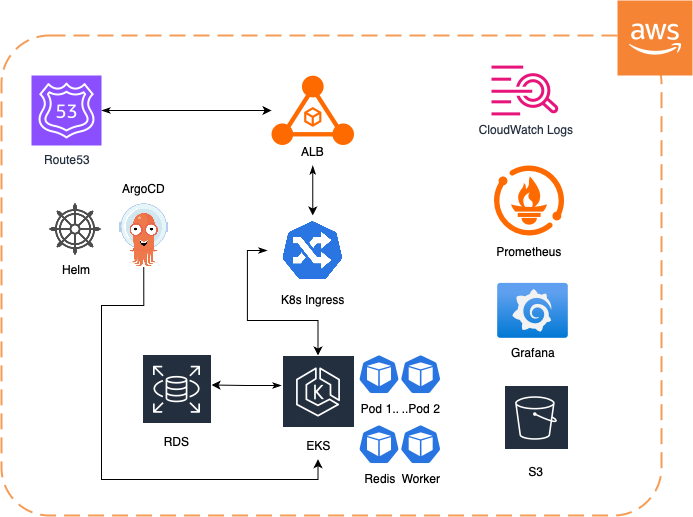
The CDOps Tech team redesigned the infrastructure and deployment workflow using Kubernetes and GitOps principles.
The platform was migrated to Amazon EKS, introducing automation across the deployment pipeline and making the system more resilient and scalable.
Key Implementations
Infrastructure as Code
Provisioned the Kubernetes environment using Terraform with reusable infrastructure modules.
Containerized Application Services
All services were Dockerized and deployed using Kubernetes resources such as Deployments, Services, and Ingress.
Standardized Deployments with Helm
Created Helm charts to make deployments consistent, repeatable, and easier to manage.
GitOps Deployment Workflow
Integrated ArgoCD to automate deployments using Git as the single source of truth.
Automatic Scaling and Self-Healing
Implemented Horizontal Pod Autoscaling so workloads scale automatically with traffic demand.
Observability and Monitoring
Added Prometheus and Grafana for monitoring and centralized logs using AWS CloudWatch.
The Results
Once the new infrastructure was deployed, the impact was immediate.
- 99.95% uptime in the first 90 days after migration
- Faster releases — developers now deploy multiple times per day
- Automatic scaling to handle traffic spikes
- Lower operational overhead — no need to hire a full-time DevOps engineer
Most importantly, the engineering team can now focus on building product features instead of managing infrastructure.
Key Takeaway
For growing SaaS teams, infrastructure needs to evolve alongside product development.
By implementing Kubernetes, GitOps, and Infrastructure as Code, this client gained a reliable and scalable platform that supports continuous delivery and growth.

