Building a machine learning model is often the easiest part of an AI initiative. The real challenge begins after the model is trained.
Many organizations invest heavily in machine learning projects, only to discover that moving an ML model from experimentation to production is slow, complex, and difficult to maintain. Data changes, model performance degrades, infrastructure evolves, and teams struggle to coordinate deployment and monitoring activities.
This is where MLOps comes in.
MLOps, short for Machine Learning Operations, is a set of practices that helps organizations automate, manage, deploy, monitor, and improve machine learning models throughout their entire lifecycle. By combining principles from machine learning, software engineering, and DevOps, MLOps creates reliable and scalable processes for delivering AI systems in production.
Whether you’re a data scientist, ML engineer, technology leader, or business decision-maker, understanding MLOps is becoming essential as AI moves from experimentation to everyday business operations.
MLOps Definition: What Does MLOps Mean?
As organizations deploy more AI and machine learning solutions, managing models in production has become just as important as building them. MLOps provides the framework needed to turn experimental models into reliable business systems.
Understanding machine learning operations
MLOps stands for Machine Learning Operations. It is a set of practices, processes, and technologies that standardize and automate the machine learning lifecycle, from data preparation and model training to deployment and monitoring.
Think of MLOps as the operational layer of machine learning.
Just as DevOps helps software teams automate application development and deployment, MLOps helps data scientists, ML engineers, and operations teams automate the deployment of ML models while maintaining quality, reliability, and governance.
An effective MLOps process typically includes:
- Data preparation and validation
- Model development and experimentation
- Model training and tuning
- Testing and validation
- Deployment of ML models
- Performance monitoring
- Continuous retraining using new data
- Governance and compliance controls
- Rather than treating machine learning as a one-time project, MLOps enables organizations to manage ML systems as ongoing products that continuously improve over time.
Why MLOps matters in modern AI
The popularity of AI has created a new operational challenge. Organizations can build models faster than ever, but many struggle to move them into production and maintain them successfully.
Research consistently shows a significant gap between experimentation and deployment:
- Approximately 87% of machine learning models never reach production, often because of operational complexity, governance challenges, or deployment bottlenecks.
- A recent Forrester report found that only 10% to 15% of AI pilots successfully scale into long-term production environments.
- According to Gartner, more than 30% of generative AI projects are expected to be abandoned after proof of concept because of poor data quality, risk management issues, and unclear business value.
These statistics highlight a common problem: building a machine learning model is no longer the primary obstacle. Operationalizing it is.
The goal of MLOps
The core goal of MLOps is to create reliable and scalable machine learning systems that can deliver business value consistently.
MLOps helps organizations:
- Automate repetitive tasks across the ML lifecycle
- Improve collaboration between data scientists and engineers
- Accelerate development and deployment
- Ensure reproducibility of ML experiments
- Monitor model performance in production
- Detect model drift and data quality issues
- Support governance and compliance requirements
- Reduce operational risk
In practical terms, MLOps helps organizations move from isolated machine learning experiments to production-ready AI systems that can be trusted, monitored, and continuously improved.
Why Traditional Machine Learning Workflows Break Down
Before MLOps became widely adopted, most machine learning projects followed a highly manual workflow. While this approach can work for prototypes and small-scale experiments, it often struggles when organizations attempt to deploy models into production and manage them over time.
The common problems teams face
Traditional ML workflows typically focus on model development rather than long-term operations.
A data scientist may train a model using a specific dataset, validate results locally, and hand the project to another team for deployment. Once the model reaches production, visibility often decreases and ownership becomes unclear.
This creates several challenges.
Data changes over time
Machine learning models depend heavily on data.
As customer behavior, market conditions, or business processes evolve, new data may look very different from the dataset used during training. Without monitoring and retraining processes, model performance can decline rapidly.
Manual deployment processes
Many organizations still rely on manual deployment steps.
Moving a machine learning model between environments often requires custom scripts, manual approvals, and infrastructure changes. These processes increase delays and introduce avoidable errors.
Lack of reproducibility
Traditional ML projects often struggle to reproduce results.
Teams may lose track of:
- Training datasets
- Hyperparameters
- Model versions
- Feature engineering steps
- Infrastructure configurations
Without proper versioning, recreating previous results becomes difficult.
Limited collaboration
Machine learning projects involve multiple stakeholders, including:
- Data scientists
- Machine learning engineers
- Software engineers
- Development and operations teams
- Product leaders
When teams work in silos, communication gaps slow development and deployment efforts.
The hidden cost of poor ML operations
The impact of weak operational processes extends beyond technical issues.
Without MLOps, organizations often experience:
- Longer deployment cycles
- Higher infrastructure costs
- Compliance risks
- Reduced trust in AI systems
- Delayed business outcomes
- Increased maintenance effort
Recent enterprise research found that 82% of IT leaders experienced unexpected AI-related cost increases while attempting to scale AI initiatives, often due to governance, integration, and operational challenges.
In many cases, the problem is not the machine learning model itself. The problem is the lack of a repeatable workflow for managing the model after deployment.
Real-world example
Imagine a retailer builds an ML model to predict customer churn.
Initially, the model performs well because it was trained using historical purchasing behavior. Six months later, customer preferences shift, new products are introduced, and marketing campaigns alter buying patterns.
Without monitoring, nobody notices that prediction accuracy has dropped.
Without automated retraining, the model continues making decisions based on outdated assumptions.
Without governance, teams struggle to determine which model version is currently active.
This scenario is exactly why MLOps practices have become essential for modern machine learning projects.
What Are the Principles of MLOps?
MLOps is more than a collection of tools. It is a set of principles designed to create reliable, scalable, and maintainable machine learning systems.
These principles help organizations manage the complexity of the machine learning lifecycle while ensuring that models remain accurate and valuable in production.
Automation
Automation sits at the center of most MLOps workflows.
Tasks that are traditionally performed manually can be automated, including:
- Data validation
- Model training
- Testing
- Deployment
- Monitoring
- Retraining
Automation reduces human error, improves consistency, and allows teams to scale machine learning operations more efficiently.
Reproducibility
Teams must be able to reproduce model results consistently.
Reproducibility requires version control for:
- Datasets
- Features
- Code
- Infrastructure
- Model artifacts
When every experiment can be recreated, organizations gain confidence in model quality and decision-making.
Continuous integration
Borrowed from DevOps principles, continuous integration ensures that changes are tested frequently throughout the ML development process.
For machine learning projects, this may include:
- Data validation checks
- Model testing
- Feature validation
- Performance benchmarking
Continuous integration and continuous testing help identify problems before deployment.
Continuous delivery and deployment
MLOps extends traditional software deployment practices to machine learning systems.
Continuous delivery allows validated ML models to move through deployment pipelines efficiently, while continuous deployment automates releases when predefined criteria are met.
This reduces delays between model development and production use.
Continuous training
Unlike traditional software, machine learning models rely on changing data.
As new data becomes available, models may need to retrain automatically to maintain accuracy.
Continuous training helps organizations:
- Adapt to changing business conditions
- Reduce model drift
- Improve model performance over time
Monitoring and observability
Deploying a model is only the beginning.
- Organizations must monitor:
- Prediction accuracy
- Data quality
- Latency
- Resource usage
- Business outcomes
Monitoring enables teams to identify issues before they affect customers or business operations.
Governance and compliance
As AI adoption grows, governance becomes increasingly important.
Strong governance includes:
- Audit trails
- Access controls
- Data privacy protections
- Regulatory compliance
- Responsible AI practices
Governance helps organizations reduce risk while maintaining trust in AI systems.
Collaboration across teams
Successful MLOps requires collaboration between data scientists and engineers, along with software engineering, infrastructure, security, and business teams.
The most effective MLOps implementations remove the traditional gap between development and operations by creating shared ownership across the machine learning lifecycle.
The MLOps Lifecycle Explained
The MLOps lifecycle provides a structured approach for managing machine learning systems from initial idea to long-term production operations. Instead of treating deployment as the final step, MLOps views machine learning as a continuous process of improvement.
Business problem definition
Every successful machine learning initiative begins with a clearly defined business objective.
Examples include:
- Reducing customer churn
- Detecting fraud
- Forecasting demand
- Personalizing recommendations
Before model development begins, teams should establish measurable success metrics and expected business outcomes.
Data collection and preparation
Data serves as the foundation of every ML project.
This stage involves:
- Collecting raw data
- Cleaning and validating records
- Removing inconsistencies
- Preparing datasets for training
Poor data quality remains one of the leading causes of AI project failure.
Feature engineering
Feature engineering transforms raw data into variables that improve model performance.
Examples include:
- Customer lifetime value calculations
- Purchase frequency metrics
- Behavioral indicators
- Aggregated business metrics
Well-designed features often have a greater impact than selecting a different algorithm.
Model development
Data scientists and machine learning engineers develop and evaluate multiple models.
Activities include:
- Algorithm selection
- Hyperparameter tuning
- Experiment tracking
- Performance evaluation
The goal is to identify the machine learning model that best addresses the business problem.
Model validation
Before deployment, models must undergo rigorous testing.
Validation may include:
- Accuracy testing
- Bias detection
- Robustness testing
- Security assessments
- Compliance reviews
This step ensures the model is ready for production use.
Deployment
Once approved, the ML model moves into production.
Deployment methods may include:
- Batch inference
- Real-time APIs
- Edge deployment
- Cloud-based deployment
Many organizations use AWS services such as SageMaker for MLOps to automate deployment and infrastructure management.
Monitoring
After deployment, teams continuously track model performance.
Key metrics often include:
- Prediction accuracy
- Data drift
- Concept drift
- Latency
- Resource utilization
- Business KPIs
Monitoring ensures models remain effective under real-world conditions.
Retraining and optimization
As new data enters the system, models may require updates.
Automated retraining workflows help organizations:
- Maintain accuracy
- Adapt to changing environments
- Improve predictions
- Reduce manual intervention
This creates an end-to-end MLOps lifecycle where models continuously evolve rather than becoming outdated after deployment.
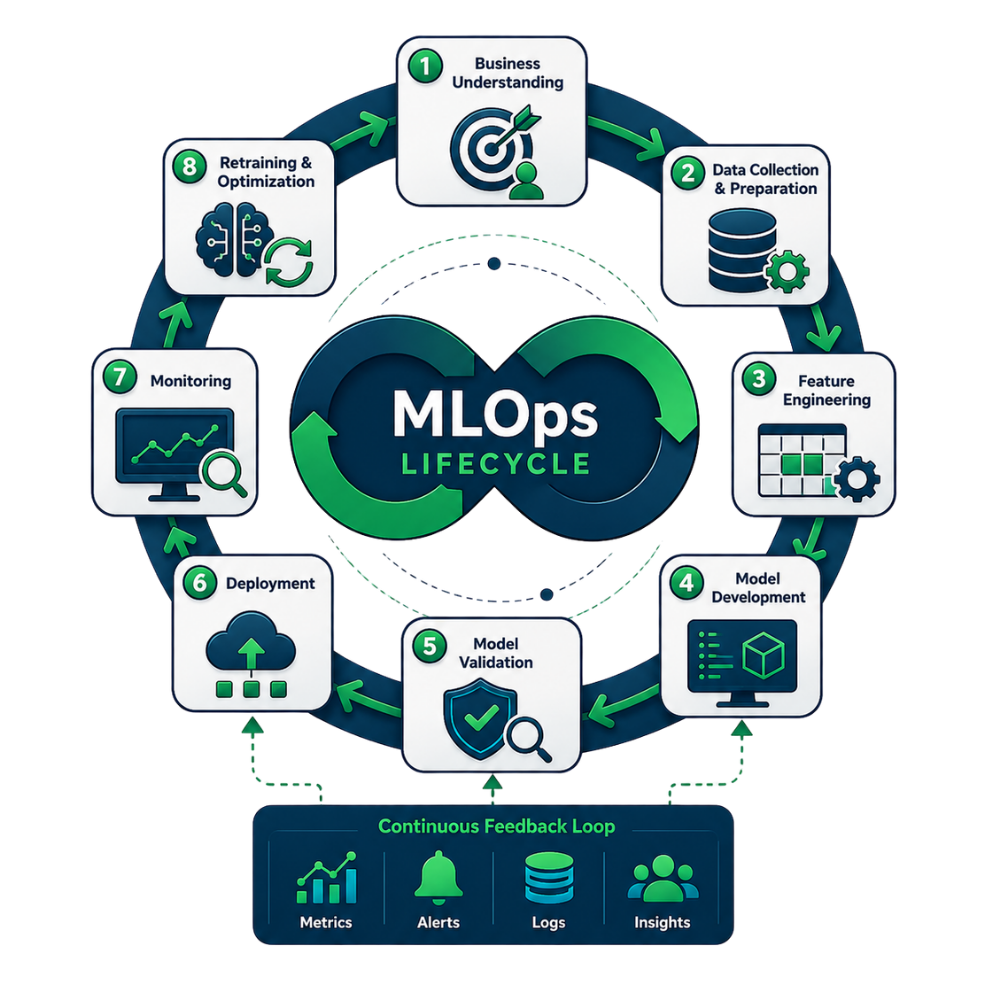
Ultimately, the machine learning lifecycle is not a straight line. It is a continuous loop of learning, deployment, monitoring, and improvement that allows AI systems to deliver long-term business value.
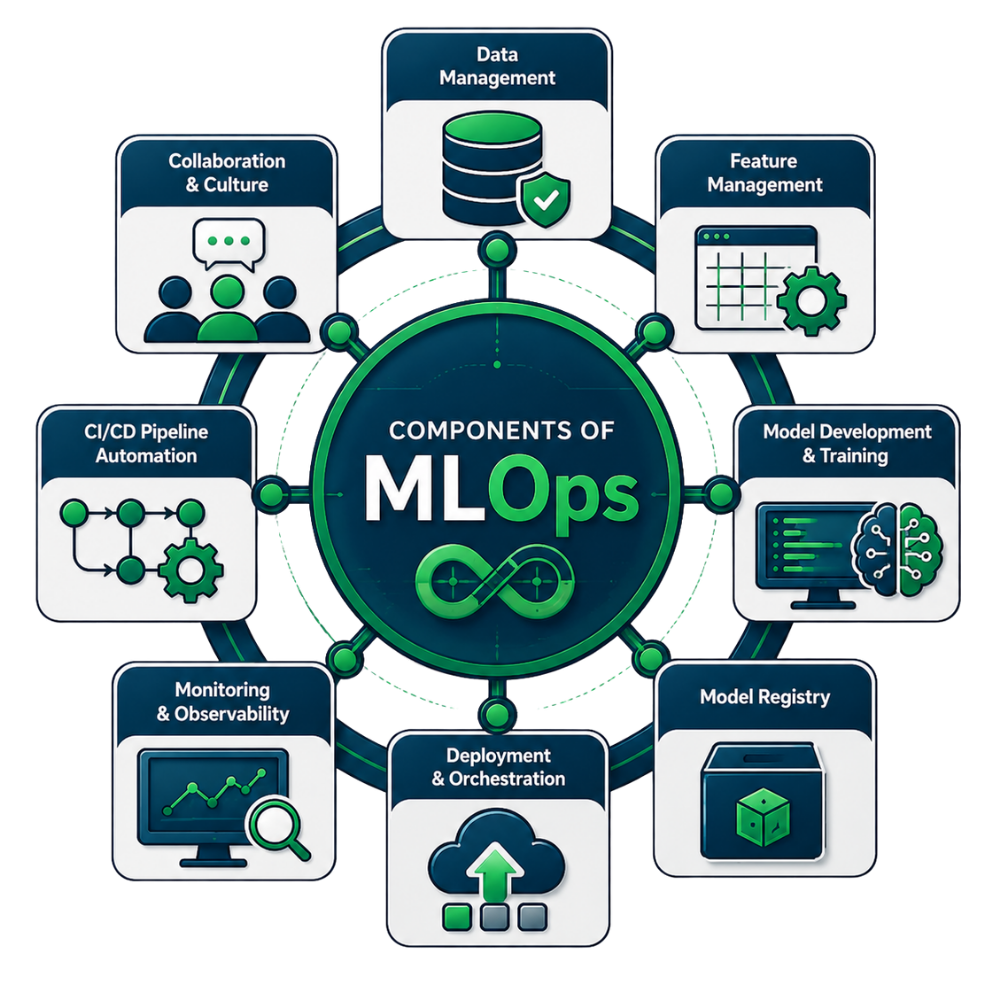
Components of MLOps
While MLOps is often described as a process, it’s easier to understand when broken down into its core components. These components work together to create a reliable framework for managing machine learning models from development through production and ongoing optimization.
Organizations may use different tools and workflows, but most successful MLOps implementations include the following building blocks.
Data management
Machine learning systems depend on high-quality data.
Data management focuses on collecting, storing, validating, and versioning datasets throughout the machine learning lifecycle. Teams need visibility into where data comes from, how it changes, and which datasets were used to train specific models.
Key activities include:
- Data ingestion
- Data validation
- Data lineage tracking
- Dataset version control
- Data quality monitoring
Without strong data management, even the most advanced ML model can produce unreliable results.
Feature stores
Feature stores help organizations manage reusable features across multiple machine learning projects.
Instead of repeatedly creating the same variables for different models, teams can centralize feature engineering efforts and ensure consistency between training and inference environments.
Benefits include:
- Faster model development
- Reduced duplication
- Improved consistency
- Better collaboration between data scientists and ML engineers
Experiment tracking
Machine learning development often involves hundreds or thousands of experiments.
Experiment tracking systems record:
- Model versions
- Hyperparameters
- Training datasets
- Evaluation metrics
- Training results
This improves reproducibility and allows teams to compare experiments efficiently.
Popular MLOps tools for experiment tracking include MLflow, Weights & Biases, and Neptune.
Model registry
A model registry acts as a central repository for approved machine learning models.
It stores:
- Model versions
- Metadata
- Approval status
- Deployment history
- Performance records
Registries help organizations manage the transition from experimentation to production while maintaining governance controls.
CI/CD pipelines for machine learning
Continuous Integration and Continuous Delivery (CI/CD) are foundational components of MLOps and DevOps.
In machine learning environments, CI/CD pipelines automate:
- Code testing
- Data validation
- Model validation
- Deployment workflows
- Rollback procedures
These automated pipelines help reduce deployment errors and accelerate delivery.
Infrastructure and containerization
Machine learning workloads often require consistent environments across development, testing, and production.
Containerization technologies such as Docker and Kubernetes allow teams to package applications and models in portable environments.
This supports:
- Reliable deployment
- Scalability
- Infrastructure consistency
- Resource optimization
Many organizations use AWS, Azure, or Google Cloud to manage infrastructure for machine learning operations.
Monitoring and observability
Monitoring provides visibility into how models perform after deployment.
Teams typically track:
- Prediction accuracy
- Latency
- Resource consumption
- Data drift
- Concept drift
- Business KPIs
Observability helps identify issues before they affect users or business outcomes.
Security and governance
As AI systems become more critical, governance requirements continue to grow.
Security and governance controls help organizations:
- Protect sensitive data
- Meet regulatory requirements
- Maintain audit trails
- Control model access
- Reduce operational risk
This component is becoming increasingly important as AI regulations evolve globally.
Documentation and collaboration
Effective MLOps requires strong communication across data science, engineering, operations, and business teams.
Documentation ensures knowledge is preserved throughout the machine learning lifecycle and reduces dependency on individual contributors.
Together, these components of MLOps create a structured framework for building, deploying, and maintaining production-grade ML systems.
Benefits of MLOps
The value of MLOps extends far beyond automation. Organizations adopt machine learning operations because it helps them scale AI initiatives more efficiently while reducing risk and improving operational consistency.
The benefits become even more significant as the number of machine learning projects grows.
Faster model deployment
One of the most visible benefits of MLOps is faster deployment.
Automated workflows reduce the time required to move a machine learning model from development into production.
According to the 2024 State of MLOps report from ClearML, organizations with mature MLOps capabilities reported significantly shorter development-to-production cycles compared to teams relying on manual workflows.
Instead of spending weeks coordinating deployment activities, teams can deploy validated models through automated pipelines.
Improved collaboration
Machine learning projects involve multiple stakeholders.
Data scientists focus on model development. ML engineers manage infrastructure and deployment. Operations teams ensure reliability and performance.
MLOps provides shared workflows, tooling, and processes that improve collaboration across these groups.
This reduces handoff delays and creates clearer ownership throughout the machine learning lifecycle.
Better model performance
Deploying a model is not enough.
Organizations need visibility into model performance over time.
MLOps enables:
- Continuous monitoring
- Drift detection
- Automated retraining
- Performance optimization
This helps maintain prediction accuracy as business conditions and datasets evolve.
Reduced operational risk
Manual processes increase the likelihood of errors.
MLOps helps reduce risk through:
- Automation
- Standardized workflows
- Version control
- Governance controls
- Monitoring systems
This creates more reliable and scalable machine learning environments.
Increased scalability
As organizations expand their AI initiatives, manual processes become difficult to sustain.
MLOps allows teams to manage dozens or even hundreds of ML models without increasing operational complexity at the same rate.
This scalability is particularly important for enterprises running multiple AI products simultaneously.
Improved governance and compliance
Regulatory requirements surrounding AI continue to increase.
MLOps supports governance through:
- Audit logs
- Data lineage tracking
- Access controls
- Model versioning
- Approval workflows
These capabilities make compliance efforts significantly easier.
Lower long-term costs
While implementing MLOps requires investment, it often reduces costs over time.
A McKinsey survey found that organizations successfully scaling AI generate greater operational efficiencies and measurable cost savings compared to organizations struggling with fragmented AI initiatives.
By automating repetitive tasks and reducing production failures, MLOps helps organizations use resources more efficiently.
Better return on AI investments
Many organizations spend heavily on machine learning but struggle to generate measurable business value.
MLOps helps bridge this gap by ensuring models remain reliable, monitored, and aligned with business objectives after deployment.
For decision-makers, this is often the most important outcome.
MLOps and DevOps: What's the Difference?
MLOps evolved from many of the same ideas that made DevOps successful. Both approaches aim to improve collaboration, increase automation, and accelerate delivery. However, machine learning introduces additional challenges that traditional software development does not face.
Understanding the difference between MLOps and DevOps helps organizations choose the right processes and tools for AI initiatives.
What is DevOps?
DevOps is a set of practices that combines software development and operations.
Its primary goals are to:
- Improve collaboration
- Accelerate software delivery
- Increase deployment reliability
- Automate infrastructure management
- Reduce operational bottlenecks
DevOps transformed how organizations build and deploy software applications by emphasizing automation and continuous improvement.
Similarities between MLOps and DevOps
Both disciplines share several foundational principles.
Common practices include:
- Automation
- Continuous integration
- Continuous delivery
- Infrastructure as code
- Monitoring
- Collaboration
In many organizations, MLOps teams work closely with existing DevOps teams.
Difference between MLOps and DevOps
The key difference is that machine learning systems include additional assets beyond source code.
Traditional software applications are primarily driven by code.
Machine learning systems depend on:
- Code
- Datasets
- Features
- Trained models
- Training pipelines
This adds complexity that DevOps alone was not designed to address.
| Area | DevOps | MLOps |
|---|---|---|
| Primary Focus | Software delivery | Machine learning lifecycle |
| Assets Managed | Code | Code, data, models |
| Testing | Functional testing | Data, model, and performance validation |
| Monitoring | Application metrics | Application and model metrics |
| Deployment | Software applications | Models and AI systems |
| Updates | Code changes | Code, data, and model changes |
Why MLOps extends DevOps rather than replaces it
A common misconception is that MLOps replaces DevOps.
In reality, MLOps builds on DevOps principles and extends them to address machine learning-specific challenges.
Organizations that already have mature DevOps practices often find it easier to implement MLOps because they already understand automation, CI/CD, monitoring, and infrastructure management.
Think of MLOps as DevOps plus the additional processes needed to manage data, models, training pipelines, and AI governance.
How to Implement MLOps Successfully
Many organizations understand the value of MLOps but struggle with implementation. The most successful teams avoid trying to build a fully automated system overnight.
Instead, they introduce MLOps practices gradually while focusing on business outcomes.
Assess your current ML maturity
Before investing in tools or platforms, evaluate your current environment.
Questions to ask include:
- How are models deployed today?
- Is model monitoring in place?
- Can experiments be reproduced?
- Are deployment workflows automated?
- Who owns production models?
This assessment helps identify the highest-priority improvements.
Standardize data pipelines
Reliable machine learning starts with reliable data.
Organizations should establish consistent processes for:
- Data collection
- Validation
- Transformation
- Storage
- Version control
Standardization reduces data quality issues and improves reproducibility.
Automate model training
Manual model training quickly becomes difficult to manage at scale.
Automating the ML training pipeline helps teams:
- Reduce repetitive work
- Improve consistency
- Accelerate experimentation
- Support continuous retraining
Automation should be introduced gradually to avoid unnecessary complexity.
Introduce CI/CD for ML
Machine learning projects benefit from the same deployment discipline used in software engineering.
CI/CD pipelines can automate:
- Testing
- Validation
- Deployment
- Rollbacks
- Infrastructure provisioning
This reduces deployment delays and improves reliability.
Build monitoring systems
Monitoring should be treated as a core requirement rather than an optional feature.
Teams should track:
- Model performance
- Data quality
- Prediction accuracy
- Infrastructure metrics
- Business KPIs
Monitoring provides the visibility needed to maintain healthy ML systems.
Establish governance policies
Governance becomes increasingly important as AI adoption expands.
Organizations should define policies covering:
- Access controls
- Model approvals
- Audit trails
- Compliance requirements
- Responsible AI practices
Strong governance helps reduce operational and regulatory risks.
Scale across teams
Once foundational MLOps workflows are established, organizations can expand adoption across departments and business units.
The goal is not simply to deploy more models. The goal is to create repeatable, reliable processes that support long-term AI growth.
Need help operationalizing machine learning?
MLOps Maturity Model
Not every organization needs fully automated MLOps from day one. Most teams progress through several stages of maturity as their machine learning capabilities evolve.
Understanding your current MLOps level can help prioritize investments and set realistic expectations.
Level 0: Manual processes
At this stage, machine learning workflows are largely manual.
Characteristics include:
- Notebook-based development
- Manual deployments
- Limited monitoring
- Minimal automation
- Ad hoc collaboration
This level is common among organizations just beginning their AI journey.
Level 1: Automated training
Teams begin introducing automation into model development workflows.
Common capabilities include:
- Automated training jobs
- Experiment tracking
- Dataset versioning
- Basic CI processes
This stage improves reproducibility and reduces manual effort.
Level 2: Automated deployment
Organizations expand automation into production environments.
Capabilities typically include:
- CI/CD pipelines
- Automated deployment
- Model registries
- Production monitoring
- Governance workflows
At this level, machine learning operations become more predictable and scalable.
Level 3: Fully automated MLOps
This represents a mature end-to-end MLOps environment.
Capabilities often include:
- Continuous training
- Automated retraining
- Drift detection
- Automated testing
- Comprehensive governance
- Enterprise-wide monitoring
According to Deloitte’s State of Generative AI research, organizations with mature AI operating models are significantly more likely to achieve measurable business value from AI investments than organizations with fragmented processes.
How to assess your organization
Most organizations operate somewhere between Levels 1 and 2.
A useful assessment framework includes evaluating:
- Automation coverage
- Deployment frequency
- Monitoring maturity
- Governance controls
- Team collaboration
- Tool standardization
The goal is not necessarily to reach the highest MLOps level immediately. Instead, organizations should focus on adopting the capabilities that solve their most pressing operational challenges while supporting future growth.
As AI adoption accelerates, MLOps maturity is becoming an increasingly important competitive advantage for organizations seeking to scale machine learning operations successfully.
MLOps Platforms and Tools
As machine learning operations mature, organizations need tools that help automate workflows, improve collaboration, and manage models at scale. The right MLOps platform can reduce operational complexity while supporting everything from experimentation to deployment and monitoring.
Rather than relying on a single solution, most organizations build an MLOps ecosystem that combines multiple tools across the machine learning lifecycle.
What is an MLOps platform?
An MLOps platform is a collection of technologies that supports the development, deployment, monitoring, and management of machine learning models.
A typical platform helps teams:
- Manage datasets
- Track experiments
- Automate ML pipelines
- Deploy models
- Monitor production performance
- Enforce governance policies
The goal is to provide a consistent workflow that supports collaboration between data scientists, ML engineers, and operations teams.
Open-source MLOps tools
Many organizations start with open-source solutions because they offer flexibility and strong community support.
Popular MLOps tools include:
MLflow
MLflow is one of the most widely used platforms for:
- Experiment tracking
- Model registry management
- Model packaging
- Deployment workflows
It integrates with many machine learning frameworks and cloud environments.
Kubeflow
Kubeflow extends Kubernetes for machine learning workloads.
It supports:
- Model training
- Pipeline orchestration
- Hyperparameter tuning
- Scalable deployment
Kubeflow is often used by organizations building complex ML infrastructure.
Apache Airflow
Airflow helps orchestrate data workflows and ML pipelines.
Teams use it to automate:
- Data ingestion
- Feature engineering
- Model training
- Scheduled retraining
- DVC
Data Version Control (DVC) brings version control principles to datasets and machine learning projects.
It helps improve reproducibility and collaboration.
Feast
Feast is a popular feature store that helps teams manage and reuse machine learning features across projects.
Cloud-based MLOps platforms
Cloud providers offer managed services that simplify infrastructure management.
AWS SageMaker
AWS SageMaker provides end-to-end machine learning capabilities, including:
- Data preparation
- Model training and tuning
- Deployment
- Monitoring
- Governance
Many organizations use SageMaker for MLOps because it reduces operational overhead while supporting enterprise-scale workloads.
Azure Machine Learning
Microsoft’s platform provides integrated tools for managing machine learning projects across development and production environments.
Google Vertex AI
Vertex AI combines machine learning services into a unified platform that supports the entire ML lifecycle.
Databricks
Databricks combines data engineering, analytics, and machine learning into a single environment.
It is widely used for large-scale AI and data science initiatives.
How to choose the right MLOps platform
There is no universal best platform.
The right choice depends on:
- Team size
- Existing infrastructure
- Compliance requirements
- Budget
- Internal expertise
- Scalability needs
Organizations should focus on solving operational challenges rather than selecting tools based solely on popularity.
MLOps on AWS
AWS has become one of the most widely adopted cloud platforms for machine learning operations. Its services support organizations at every stage of the machine learning lifecycle, from data analysis and model training to deployment and monitoring.
For teams already using AWS infrastructure, adopting MLOps can often be faster because many required services are already available within the ecosystem.
AWS services commonly used for MLOps
Several AWS services play a central role in machine learning operations.
Amazon SageMaker
SageMaker serves as AWS’s primary machine learning platform.
It provides capabilities for:
- Data preparation
- Model training and tuning
- Experiment tracking
- Model deployment
- Monitoring
- Automated ML workflows
SageMaker for MLOps allows organizations to automate many operational tasks that would otherwise require custom infrastructure.
Amazon S3
Amazon S3 is commonly used for:
- Dataset storage
- Model artifacts
- Backup management
- Training data repositories
- Amazon ECR
Elastic Container Registry (ECR) stores container images used for machine learning deployments.
Amazon ECS and EKS
These services help deploy and manage containerized ML applications at scale.
Amazon CloudWatch
CloudWatch provides monitoring and observability capabilities for infrastructure, applications, and machine learning workloads.
Typical AWS MLOps architecture
A common AWS workflow includes:
- Data stored in Amazon S3
- Model training in SageMaker
- Model registration and approval
- Deployment through managed endpoints
- Continuous monitoring with CloudWatch
- Automated retraining triggered by performance thresholds
This architecture helps organizations automate large portions of the machine learning lifecycle while maintaining governance and scalability.
Benefits of using AWS for MLOps
Organizations often choose AWS because it offers:
- Managed infrastructure
- Enterprise-grade security
- Global scalability
- Built-in monitoring
- Flexible deployment options
According to AWS, thousands of organizations use SageMaker to accelerate machine learning development while reducing operational complexity.
MLOps for Generative AI and LLMs
The rise of generative AI has expanded the scope of machine learning operations. While traditional MLOps practices remain important, large language models (LLMs) introduce new challenges that require additional workflows, tooling, and governance controls.
As organizations deploy AI assistants, chatbots, copilots, and retrieval-augmented generation (RAG) systems, MLOps continues to evolve.
Why traditional MLOps isn’t enough
Traditional machine learning models are often smaller, more predictable, and easier to retrain.
LLMs introduce challenges such as:
- Massive training datasets
- Higher infrastructure costs
- Prompt management
- Hallucinations
- Model safety concerns
- Complex evaluation requirements
These challenges require additional operational controls beyond standard machine learning workflows.
What is LLMOps?
LLMOps is an extension of MLOps focused specifically on managing large language models and generative AI systems.
It includes practices for:
- Prompt versioning
- Model evaluation
- Safety testing
- Vector database management
- Retrieval pipeline monitoring
- AI governance
Think of LLMOps as a specialized layer within the broader MLOps ecosystem.
Additional challenges for generative AI
Prompt management
Prompt changes can significantly impact model behavior.
Organizations need version control and testing processes for prompts just as they do for code.
Vector databases
Many AI applications rely on vector databases to support semantic search and retrieval.
These databases become a critical part of the production workflow.
AI safety and compliance
Generative AI introduces risks related to:
- Bias
- Toxic outputs
- Intellectual property concerns
- Privacy violations
Organizations need governance frameworks to address these risks.
Cost optimization
Running LLMs can be expensive.
Monitoring inference costs, resource consumption, and model usage becomes essential for maintaining ROI.
MLOps vs LLMOps
MLOps manages machine learning systems broadly.
LLMOps focuses specifically on large language models and generative AI applications.
Organizations deploying advanced AI solutions often require both disciplines working together.
Security, Compliance, and Legal Considerations
As AI becomes more integrated into business operations, security and compliance can no longer be treated as afterthoughts. Machine learning systems often process sensitive data, influence business decisions, and operate under increasing regulatory scrutiny.
Strong governance protects both organizations and customers.
Data privacy requirements
Many machine learning models rely on customer, employee, or operational data.
Organizations must ensure compliance with privacy regulations such as:
- GDPR
- CCPA
- HIPAA
- Industry-specific regulations
Privacy controls should be built into machine learning workflows from the beginning.
Model governance
Model governance provides oversight throughout the machine learning lifecycle.
Key governance practices include:
- Approval workflows
- Version control
- Documentation standards
- Risk assessments
- Performance reviews
Governance improves accountability and transparency.
Explainability and audit trails
Organizations increasingly need to explain how AI systems make decisions.
Audit trails help track:
- Data sources
- Model versions
- Training configurations
- Deployment history
This information supports compliance efforts and simplifies investigations when issues arise.
Emerging AI regulations
Governments worldwide are introducing AI-specific regulations.
Examples include:
- The EU AI Act
- Sector-specific compliance frameworks
- Industry governance standards
Organizations that establish governance controls early will be better positioned to adapt as regulations evolve.
Responsible AI practices
Responsible AI focuses on building systems that are:
- Fair
- Transparent
- Secure
- Accountable
These principles are becoming an essential part of modern machine learning operations.
Common MLOps Mistakes to Avoid
Even well-funded AI initiatives can struggle when operational processes are overlooked. Many organizations encounter the same challenges during MLOps implementation.
Understanding these common mistakes can help teams avoid unnecessary delays and costs.
Ignoring data quality
Many machine learning failures originate from poor data rather than poor models.
Without data validation and monitoring, teams risk training models on incomplete, outdated, or inaccurate information.
Overengineering too early
Some organizations attempt to build a fully automated enterprise platform before proving business value.
This often increases complexity without delivering meaningful results.
Start with the most critical workflows and expand gradually.
Not monitoring model drift
Machine learning models change in effectiveness over time.
Without monitoring, performance issues can remain hidden for months before they impact business outcomes.
Lack of ownership
When responsibilities are unclear, production models often fall into operational gaps.
Successful teams establish clear ownership across:
- Data science
- Engineering
- Operations
- Governance
Choosing too many tools
The MLOps market continues to expand rapidly.
Using too many disconnected tools can increase maintenance requirements and create unnecessary complexity.
Focus on building a streamlined workflow rather than maximizing tool count.
Treating MLOps as a one-time project
MLOps is not a technology purchase.
It is an ongoing set of practices that evolves alongside business requirements, infrastructure, and AI capabilities.
MLOps Best Practices
Organizations that succeed with machine learning operations typically follow a consistent set of best practices. These practices improve reliability, scalability, and long-term maintainability.
Start small and automate gradually
Avoid attempting to automate everything immediately.
Begin with high-impact workflows such as:
- Model deployment
- Data validation
- Monitoring
- Retraining
Expand automation as processes mature.
Version everything
Version control should extend beyond source code.
Track:
- Datasets
- Features
- Models
- Training configurations
- Infrastructure changes
This improves reproducibility and simplifies troubleshooting.
Monitor continuously
Effective monitoring should cover:
- Infrastructure metrics
- Model performance
- Data quality
- Business outcomes
Continuous visibility helps teams identify issues before they become costly.
Align MLOps with business goals
Technology alone does not create value.
Successful organizations connect machine learning initiatives to measurable business outcomes such as:
- Revenue growth
- Cost reduction
- Customer retention
- Operational efficiency
- Build cross-functional teams
Strong collaboration between data scientists, ML engineers, software engineers, security teams, and business stakeholders improves project outcomes.
Machine learning operations work best when ownership is shared rather than isolated within a single department.
Document every stage
Documentation helps preserve institutional knowledge and simplifies onboarding, governance, and troubleshooting.
It also supports compliance and audit requirements.
Ready to Build a More Reliable Machine Learning Workflow?
MLOps has evolved from a niche practice into a critical capability for organizations deploying AI at scale. As machine learning projects become more complex, teams need structured processes that support development, deployment, monitoring, governance, and continuous improvement.
Whether you’re managing a single machine learning model or building enterprise-wide AI systems, adopting the right machine learning operations strategy can help reduce risk, improve efficiency, and increase the long-term value of your AI investments.
The key is to start with practical improvements, build repeatable workflows, and gradually expand your MLOps capabilities as your organization matures.
If you’re looking for expert guidance on implementing MLOps, optimizing AI workflows, or building scalable machine learning infrastructure, our team at CDops Tech can help. We work with organizations to design, deploy, and manage reliable AI and machine learning solutions that deliver measurable business outcomes.
Need help with your MLOps strategy or implementation? Contact us today to discuss your goals and explore the right approach for your organization.

